Hello!
I am a Data & Earth Scientist at KoBold Metals.
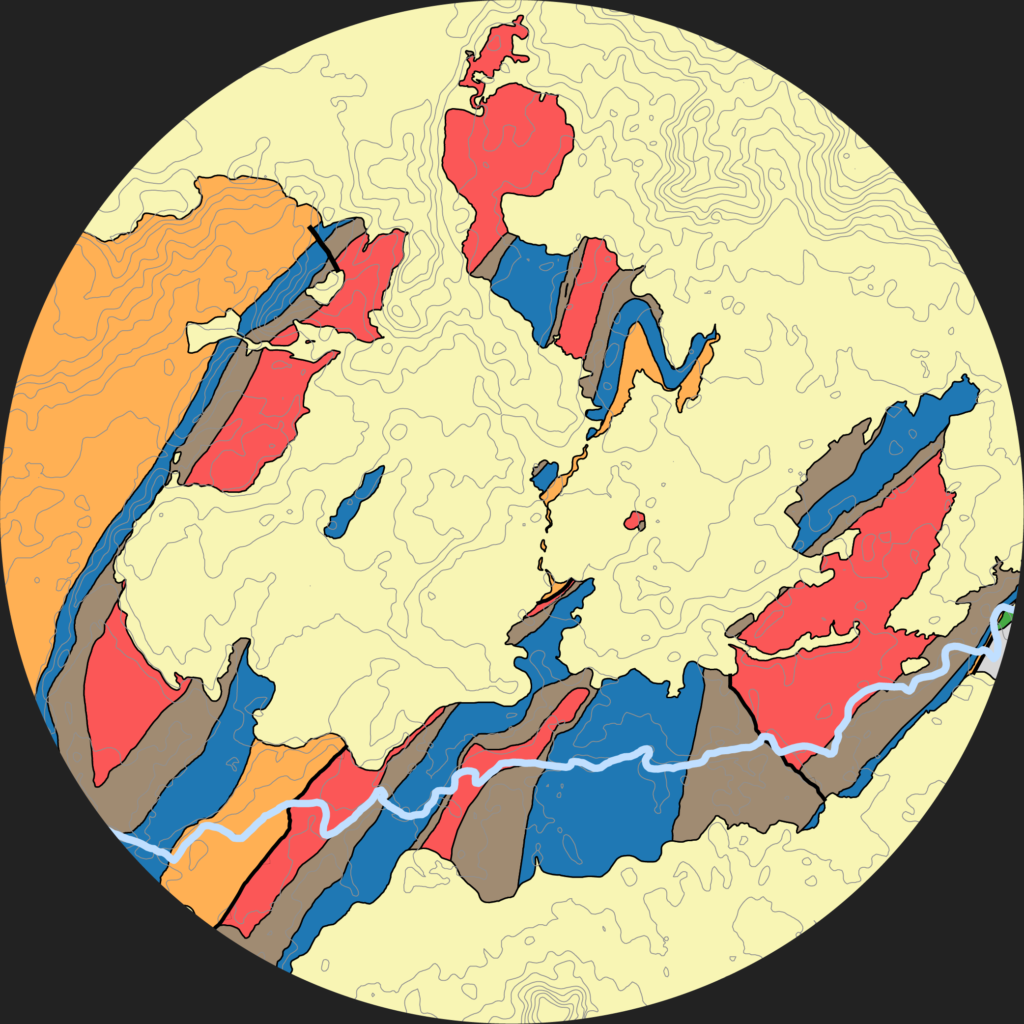
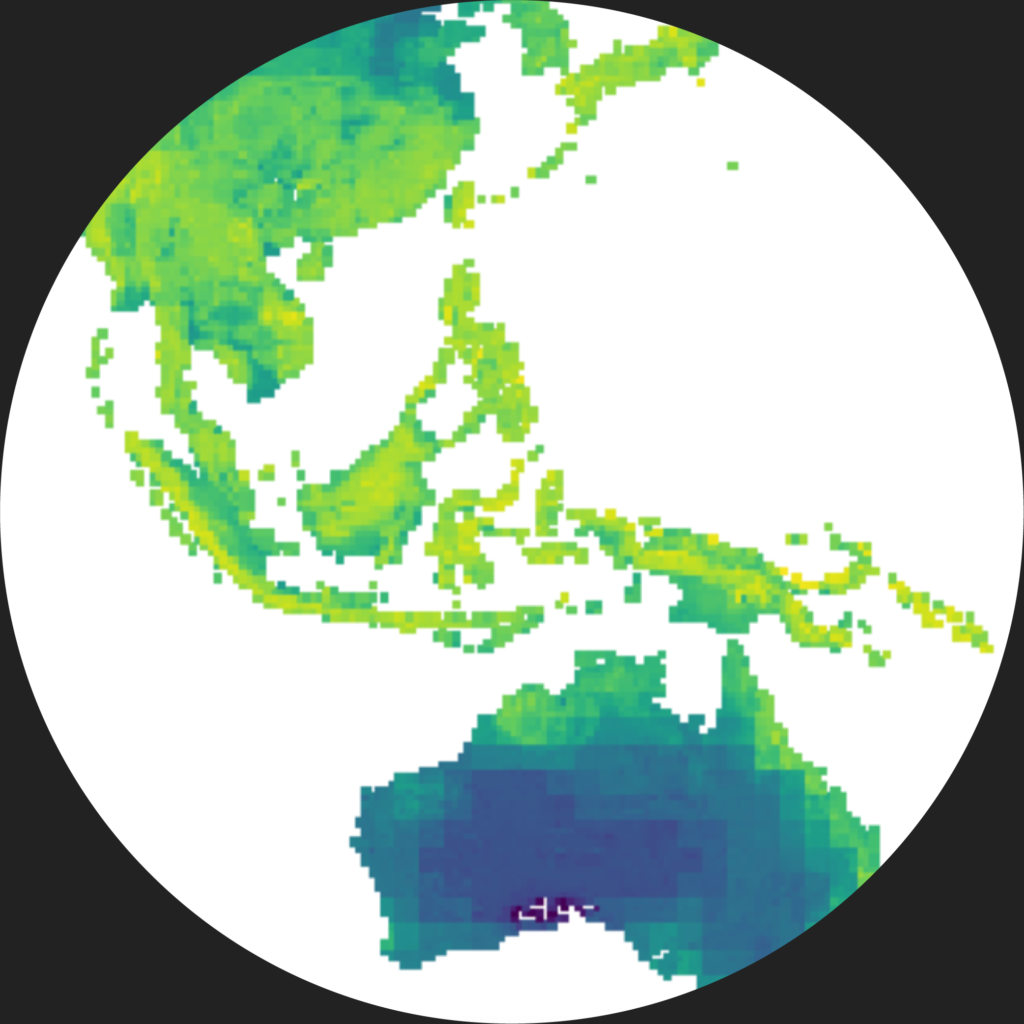
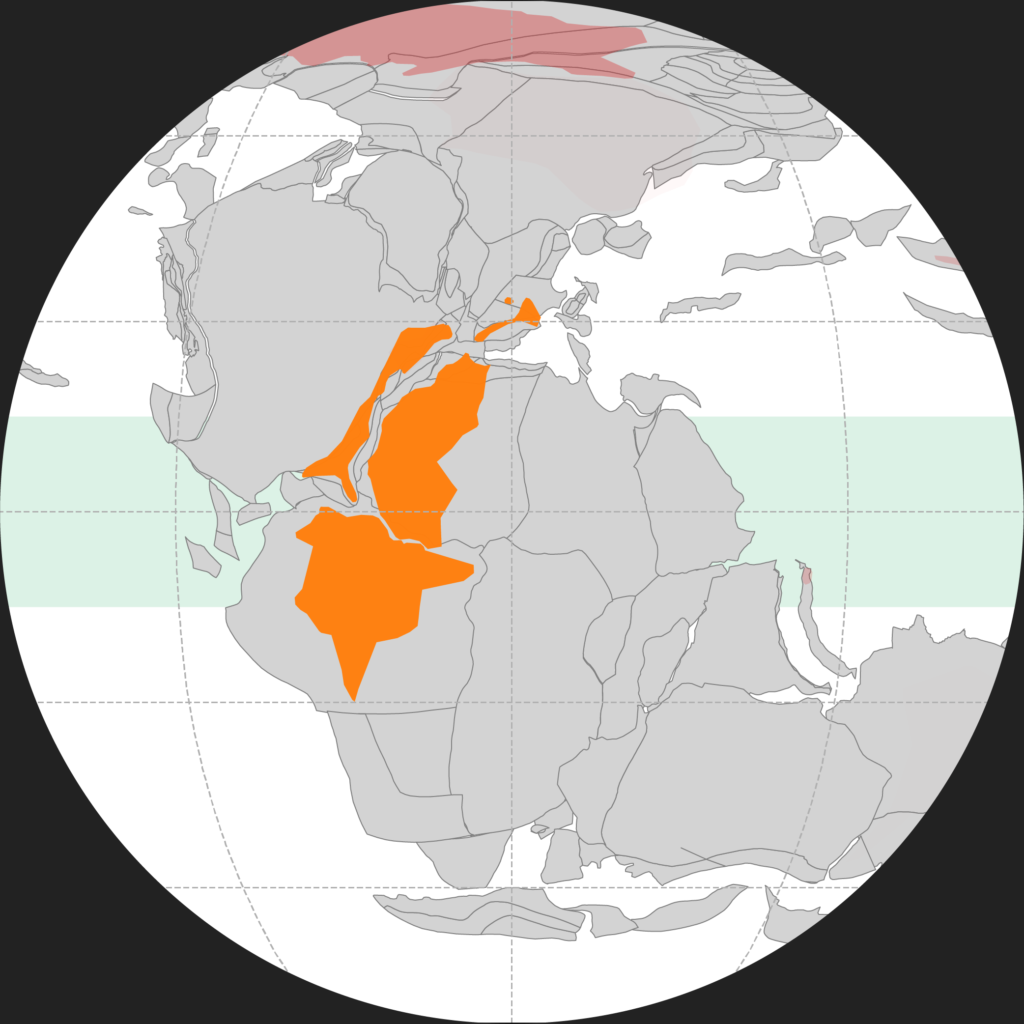
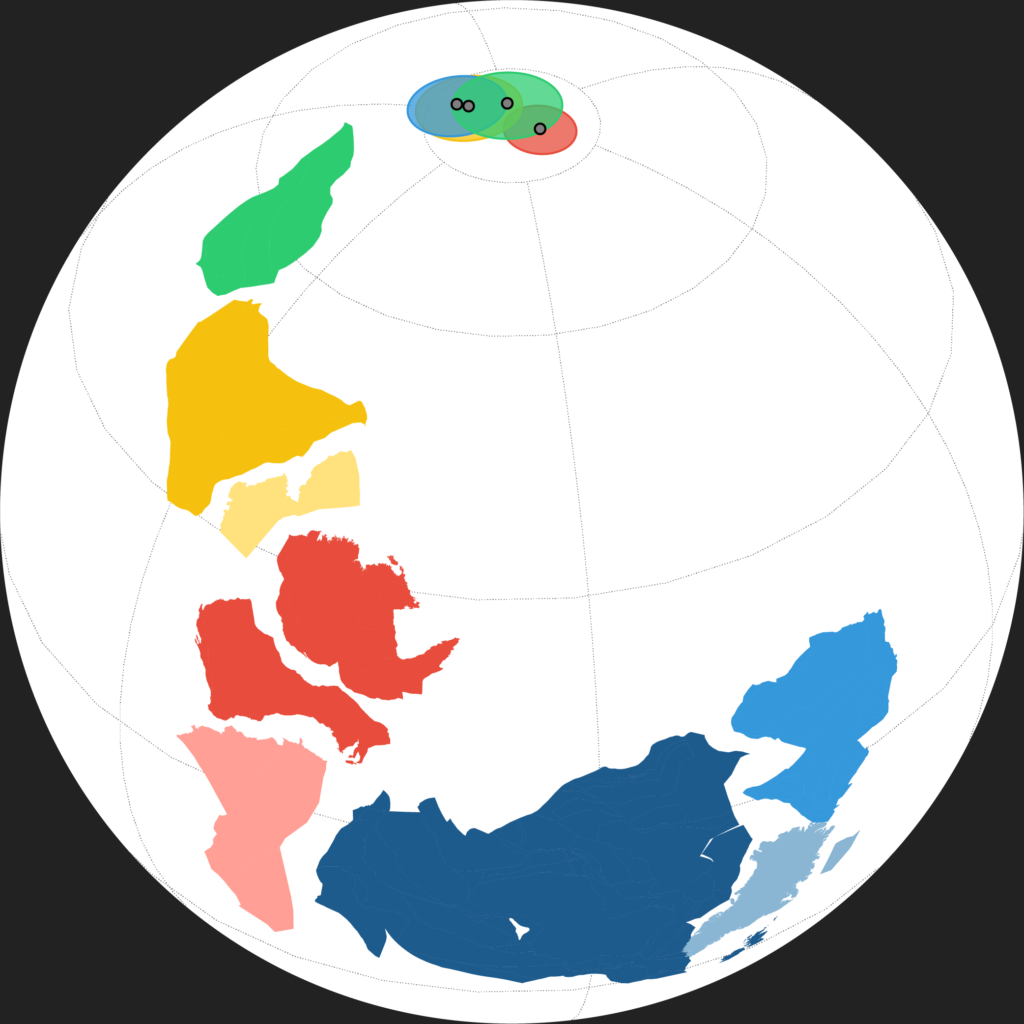
I investigate a variety of Earth-related data using machine learning and other data science techniques to identify new sources of essential battery materials.
My work involves:

data science and machine learning

field observations and measurements

lab analyses on collected samples
gauges indicate relative time spent in each